全文検索(Opensearch/Elasticsearch + FESS)によるデスクトップ検索の面倒を解決する方法
前置き
以下、この Blog の読み手の興味を惹かない内容(=検索に関する技術的な細部)なので skip 推奨。この手の小細工はすぐに忘れるので 記録/保存 するのが目的。
何が問題か?
本 Blog では記事が累積し、非公開の内部 資料/記事 も含めると既に文書総数が数万件になっている。さらに 記事/文書 は複数のサイト(+local) に跨っている。加えて個々の記事は比較的長く、文字起こしを含む場合は 200KiB を超えるものも少なくない。ちなみに文庫本一冊に含まれる文章の情報量は 200~300 KiB 程度。
この状況で、どうやって過去記事を効率的に検索するか? これが問題となる。
具体的にいえば、
- 複数のサイト(+local) に跨る数万件の記事、
- それも 200KbiB を超える長文の記事を含む文書群を、
- 効率的に「全文検索」し、
- 検索結果を一瞥でわかるように表示し、
- かつ、必要となれば(画像や動画を含めた)完全な形で表示できる(=元サイトの記事を直接アクセスして表示)
ことが必要となる。この対処方法について、以下で詳しく述べる。
目次
従来の全文検索の方法とその問題点
従来の全文検索の方法
従来(= 2025年の中頃まで)は、以下の方法を用いて全文検索を実現していた。概略、
-
複数のサイトに跨った BLog 記事を(記事内に埋め込まれた映像を含めて)全て crawling し、
-
取得した記事データをデータベースに格納
-
GUI の皮を被せた専用アプリで、このデータベースをアクセスし、結果を表示
…という古く単純な手法だった。効率化のために細部では様々な小細工を施しているが、大枠では
- crawling → データベース格納 → データベースを SQL で検索
という流れ。
この方法の問題点
以下の問題点がある。
-
自作ツールによる定期的な crawling と、データベースの更新が必要
-
データサイズの増加に伴う検索での応答速度の低下
-
高度な全文検索(曖昧検索、形態素解析など)に対応できない
-
検索手順がシンプルではない
この 4 について補足すると、
- (1) 専用アプリで検索する。
- (2) ヒットした記事のテキスト部分が専用アプリのテキスト表示欄に表示される。
- (3) 記事に埋め込まれた映像(静止画 or 動画)を含めて完全な形で表示したい場合は、"元サイト記事を表示"ボタンを押すことで Web ブラウザで表示する。
という流れになる。つまり、専用アプリと Web ブラウザを行き来することとなり、検索の手順がシンプルではない。
Opensearch/Elasticsearch + FESS での問題点
上述の 1~4 の問題を解消するために、2025年中頃から Opensearch+FESS による全文検索を採用した。この方法では、FESS の検索画面から全文検索することになるが、以下の問題があることが判明した。
1. markdwon 文書の表示が手間
検索でヒットした文書が単純なテキスト文書(*.txt) ならば、FESS 画面(=ブラウザ)にそのまま表示される。
だが、txt 以外の文書、例えば markdown 文書なら、download 経由となる。つまり、
-
(ブラウザ上の)FESS 画面で検索を実行
-
検索にヒットした文書がリストアップされ、
-
ユーザが特定の文書のリンクをクリック
-
そのリンク先が *.txt 以外ならブラウザは download を実行
-
(download したファイル種別毎に起動アプリを設定可能なブラウザであれば)"markdown viewer"(ブラウザ用 addon )経由で表示してよいかどうかをユーザに確認する pop-up 画面(下がその具体例)が 「毎回常に」 表示される。
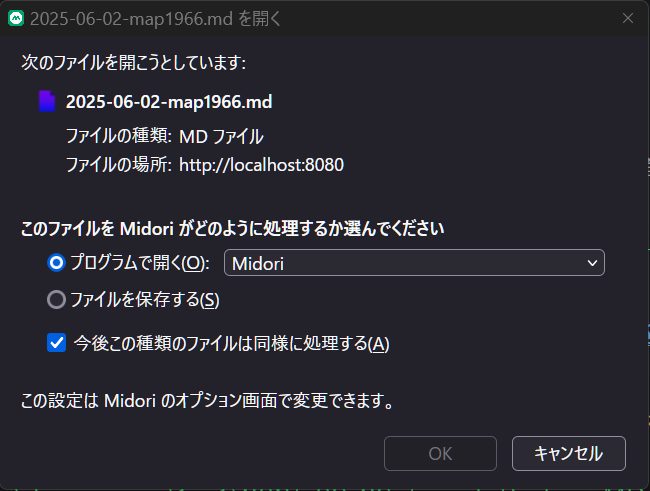
-
ユーザがその pop-up 画面で OK のボタンをクリックした後に、やっとmarkdown viewer 経由で markdown 文書がブラウザ画面に表示される。長大なファイルだと OK が有効になるまで待たされるというオマケ付き。
…という流れになる。ブラウザにもよるが、この 6. では最低でも 1-2回のリクック(or Tab + return のキー操作)が必要になる(*1)。
この操作はデフォルト設定などで省略することはできず、毎回必ず必要になる。やってみればわかるが、これはとてもダルい。対象となる語句(の AND OR の組み合わせ)を様々に変えて、深く掘り下げて検索しよう…という意欲がゴッソリと削られる。
さらに、download 用フォルダーの中は *.md ファイルだらけとなり、定期的に手作業で掃除するか、削除用に専用の常駐アプリを作成し、起動しておく必要もある。
(*1) : 参考
この問題は、基本的には「FESS のデスクトップ検索のための設定」にからむ問題という話になる。だが、
-
Web でみかける(公式サイト以外の)対処方法の記事などは情報が古くて既に使えない。
-
公式サイトには以下のように説明されている。
Q:
Fessのトップページからの検索では、検索結果一覧でファイル名をクリックすると目的のファイルがダウンロードされて開けるのですが、FSSのJavaScript(FSS JS)を使用して、自分のサイトに設置した検索窓から検索した場合、検索結果の一覧は表示されるのですが、結果をクリックしてもファイルが開けません。
Fessのバージョンは13.16.0です。 もしかしたらデスクトップ検索の設定かと思い、下記に書かれている方法を試そうとしたのですが、このバージョンでは下記の2ファイルが存在しませんでし�た。
デスクトップ検索について
近年のブラウザ環境ではセキュリティの意識が高まり、ウェブページ上からローカルファイル (たとえば、c:\hoge.txt) を開くことができません。 そのため、 Fess では標準で Java アプレットを利用してファイルシステム上のファイルを開くことができます。 Java アプレットとは別な方法として、デスクトップ検索機能も提供しています。 デスクトップ環境はローカルPCで Fess を起動して、ファイルシステムに存在するファイルにアクセスする場合に利用することができます。 サーバー・クライアントの環境ではデスクトップ検索は利用することはできません。
ref: デスクトップ検索の設定 https://fess.codelibs.org/ja/8.0/config/desktop-search.html
(skip)
...
A:
デスクトップ検索は昔の機能なので、現在は提供していません。
おそらく、ローカルのファイルシステムをクロールした結果が開かない、という話なのだと思いますが、現在の標準的なブラウザではfile://〜のようなファイルシステムへのリンクはアクセスすることができます。これは、Fessに限った話ではなく、ブラウザがそのようにしているためです。
そして、Fessで検索すれば開くが、FSSだと開かない、という話になりますが、Fessではコンテンツプロキシという機能を提供しており、file://〜で始まるようなリンクはFessがプロキシとして代わりにfile://〜にアクセスして、httpでブラウザに��ファイルを渡しているので、ファイルシステムの内容もブラウザで表示することができます。FSSでは、file://〜から直接取得しようとするが、ブラウザが制限しているので開かない、という状態だと思います。現時点では、FSSはサイト内検索をメインターゲットにしているため、Fessのコンテンツプロキシを対応するようにFSSのJSを変更していただくか、商用サポートに依頼していただくしか、FSSで対応する方法はないと思います。
A:
Fess Site Search(FSS)もオープンソースで、github.com/codelibs/fess-site-searchにあります。 FSSを編集するのも大変だと思うので、検索APIの利用方法などを参考にして、普通にJavaScriptで書いたりしたほうが楽かもしれません。
ref: サイトに設置した検索窓から検索した場合、結果一覧からファイルが開けない - Japanese:Fess - CodeLibs Forum https://discuss.codelibs.org/t/topic/1891/3
2. markdwon 文書に埋め込まれた映像が表示されない
FESS の検索画面から検索し、ヒットした文書がリスト表示され、それを上述のダルい手順を踏んで、めでたく markdown 文書がブラウザに表示��されたとする。
ここで別の問題が生じる。 markdwon 文書に埋め込んだ多くの映像(静止画、動画)は表示されない。なぜなら、映像の在処を示す base_URL が FESS 環境と、その文書の本来の格納場所とでは異なってしまうゆえに。
これらの問題を解決する方法
概要
上述の問題を泥縄式に解決する方法はいくつもある。例えば、Opensearch/Elastcsearch と FESS の間に自前で作成した変換フィルターを咬ませる方法(前述 2. の対処)や、FESS の内部処理に手をいれる(前述 1. の対処)がある。
だが、それらの方法はエレガントではない上に、技術的難易度が高く、対処が泥沼化するリスクも高い。Opensearch/Elastcsearch や FESS の Version up への対応も面倒になる。
もっと根本的な解決法がある。それは、
- (Web ブラウザ上で実行される)FESS の 検索/表示 機能を用いず、
- 検索/表示 用の JavaScript プログラムを自作し、
- その JavaScript 内部で FESS API を介して 検索と結果(json 形式)の取得 を実行し、
- その取得データ(json 形式)を自作の JavaScript で好き勝手に加工し、
- 加工結果をブラウザに表示させる
という方法。
具体的な方法
FESS のバージョンで API の仕様が異なっているので、最初に version を明記しておく。
version
| app | version |
|---|---|
| FESS | FESS-15.2.0 |
| opensearch | opensearch-3.2.0-windows-x64 |
| java | OpenJDK21U-jdk_x64_windows_hotspot_21.0.8_9 |
FESS の公式ドキュメントと、その修正
公式サイトに FESS API を用いた 検索/結果表示 用の JavaScript のサンプルが掲載されている。
公式サイトの情報
Fess で作る Elasticsearch ベースの検索サーバー 〜 API 編 : https://fess.codelibs.org/ja/articles/article-3.html
修正が必要
上の公式サイトに掲載されたサンプルを試したところ、エラーとなって実行できない。Web ブラウザの開発者ツールでエラー箇所を調べると、API の仕様が変わっており、公式サイトのサンプルはその仕様変更が反映されていない。
サンプル JavaScript の修正版
以下、修正版を添付しておく。
修正版の fess.js
$(function(){
// (1) Fess の URL
var baseUrl = "http://localhost:8080/api/v1/documents?q=";
//var baseUrl = "http://localhost:8080/json/?q=";
// (2) 検索ボタンのjQueryオブジェクト
var $searchButton = $('#searchButton');
console.log("fess.js 起動");
// (3) 検索処理関数
var doSearch = function(event){
// (4) 表示開始位置、表示件数の取得
var start = parseInt($('#searchStart').val()),
num = parseInt($('#searchNum').val());
// 表示開始位置のチェック
if(start < 0) {
start = 0;
}
// 表示件数のチェック
if(num < 1 || num > 100) {
num = 20;
}
// (5) 表示ページ情報の取得
switch(event.data.navi) {
case -1:
// 前のページの場合
start -= num;
break;
case 1:
// 次のページの場合
start += num;
break;
default:
case 0:
start = 0;
break;
}
// 検索フィールドの値をトリムして格納
var searchQuery = $.trim($('#searchQuery').val());
console.log({searchQuery});
// (6) 検索フォームが空文字チェック
if(searchQuery.length != 0) {
var urlBuf = [];
// (7) 検索ボタンを無効にする
$searchButton.attr('disabled', true);
// (8) URL の構築
urlBuf.push(baseUrl, encodeURIComponent(searchQuery),
'&start=', start, '&num=', num);
// (9) 検索リクエスト送信
$.ajax({
url: urlBuf.join(""),
dataType: 'json',
}).done(function(data) {
// 検索結果処理
var dataResponse = data; //data.response;
console.log("response:", {dataResponse});
console.log("status:", dataResponse.status);
// (10) ステータスチェック
/*
if(dataResponse.status != 0) {
// alert("検索中に問題が発生しました。管理者にご相談ください。");
return;
}
*/
var $subheader = $('#subheader'),
$result = $('#result'),
record_count = dataResponse.record_count,
offset = 0,
buf = [];
if(record_count == 0) { // (11) 検索結果がない場合
// サブヘッダー領域に出力
$subheader[0].innerHTML = "";
// 結果領域に出力
buf.push("<b>", dataResponse.q, "</b>に一致する情報は見つかりませんでした。");
$result[0].innerHTML = buf.join("");
} else { // (12) 検索にヒットした場合
var page_number = dataResponse.page_number,
startRange = dataResponse.start_record_number,
endRange = dataResponse.end_record_number,
i = 0,
max;
offset = startRange - 1;
// (13) サブヘッダーに出力
buf.push("<b>", dataResponse.q, "</b> の検索結果 ",
record_count, " 件中 ", startRange, " - ",
endRange, " 件目 (", dataResponse.exec_time,
" 秒)");
$subheader[0].innerHTML = buf.join("");
// 検索結果領域のクリア
$result.empty();
// (14) 検索結果の出力
var $resultBody = $("<ol/>");
var results = dataResponse.data;
for(i = 0, max = results.length; i < max; i++) {
buf = [];
buf.push('<li><h3 class="title">', '<a href="',
results[i].url_link, '">', results[i].title,
'</a></h3><div class="body">', results[i].content_description,
'<br/><cite>', results[i].site, '</cite></div></li>');
$(buf.join("")).appendTo($resultBody);
}
$resultBody.appendTo($result);
// (15) ページ番号情報の出力
buf = [];
buf.push('<div id="pageInfo">', page_number, 'ページ目<br/>');
if(dataResponse.prev_page) {
// 前のページへのリンク
buf.push('<a id="prevPageLink" href="#"><<前ページへ</a> ');
}
if(dataResponse.next_page) {
// 次のページへのリンク
buf.push('<a id="nextPageLink" href="#">次ページへ>></a>');
}
buf.push('</div>');
$(buf.join("")).appendTo($result);
}
// (16) ページ情報の更新
$('#searchStart').val(offset);
$('#searchNum').val(num);
// (17) ページ表示を上部に移動
$(document).scrollTop(0);
}).always(function() {
// (18) 検索ボタンを有効にする
$searchButton.attr('disabled', false);
});
}
// (19) サブミットしないので false を返す
return false;
};
// (20) 検索入力欄でEnterキーが押されたときの処理
$('#searchForm').submit({navi:0}, doSearch);
// (21) 前ページリンクが押されたときの処理
$('#result').on("click", "#prevPageLink", {navi:-1}, doSearch)
// (22) 次ページリンクが押されたときの処理
.on("click", "#nextPageLink", {navi:1}, doSearch);
});
実行例
前述の修正版の JavaScript で検索を実行した具体例が下。markdown ファイル(*.md) をクリックすると(ダルい操作も不要、download も行われずに)即座に内容が表示される。

加工と表示のカスタマイズ
上述の fess.js は
- 検索/表示 用の JavaScript を自前で実装し、
- その JavaScript 内部で FESS API を介して 検索と結果(json 形式)の取得 を実行し、
のための骨組みでしかない。
- その取得データ(json 形式)を自前の JavaScript で好き勝手に加工し、
- 加工結果をブラウザに表示させる
部分は検索でヒットした元文書の base_URL に依存するので、それに合わせて JavaScript を書く必要がある(が、大した行数にはならない)。
あとは、必要性と好みに合わせて、
- (A) 文書の映像用 URL を置換処理した後にブラウザに表示させるか、
- (B) (FESS が crawling した local ファイルではなく、)元サイトの記事を直接ブラウザに表示させるか
を選択する2つのリンクを検索結果一覧表示に並べるなり、一律に A, B どちらの方法でアクセスするかを選択する切り替えラジオ・ボタンを画面上部に配置するなりすれば良い。
方言的記法の対処
現在、Docusaurus で採用している
なんとか、かんとか。
あーだ、こーだ。
といった方言的な Markdown 記法は、移植性が悪い。そのため、出回っている addon の markdown viewer ではどれも期待する形では表示されない。そこで、
- このような方言的な記述を廃止し、
- blockquote を独自の CSS で修飾することで外観を似せる
方法で代替えすると実用性と移植性が高い。既に作成済みの Blog 記事に含まれる先の方言的な記述は変換スクリプトで一律に自動変換すれば済む。現状でも
- 目次の自動生成
- 「AI が生成した markdown に含まれる強調表示のバグ」の対処
のためにスクリプトを咬ませているので、その延長線上にある。
(2025-10-04)