DeepSeek V3.2登場:GPT-5級のオープンソースAI
(全体俯瞰 : AI 生成) click で拡大
要旨
DeepSeek V3.2登場:GPT-5級のオープンソースAI
このソースは、最近リリースされた DeepSeek V3.2 モデル(Special および Thinking バージョン)の包括的なレビューを提供しています。
このモデルは、国際的なベンチマークにおいて、Gemini 3 Pro や GPT-5 といったトップクラスのクローズドソースAIシステムに匹敵するか、またはそれ以上のパフォーマンスを発揮すると主張されています。特に重要なのは、DeepSeek V3.2が完全なオープンソースおよびオープンウェイトモデルである点であり、これにより商用利用、スケーリング、およびファインチューニングが競合モデルと異なり可能になっています。
その高い性能は、計算コストを効率的に削減する DeepSeek Sparse Attention (DSA) 手法を含む�、三つの主要なトレーニング方法によって実現されています。また、コーディングやエージェントタスクでの強力な推論能力が実証され、さらには国際数学オリンピックでゴールドメダルレベルの結果を出すなど、数学的才能も示されています。
レビューの締めくくりとして、ユーザーはチャットウェブアプリやAPIを通じて、この高度なモデルを無料で利用できることが紹介されています。
目次
DeepSeek V3.2に関するブリーフィング文書
エグゼクティブサマリー
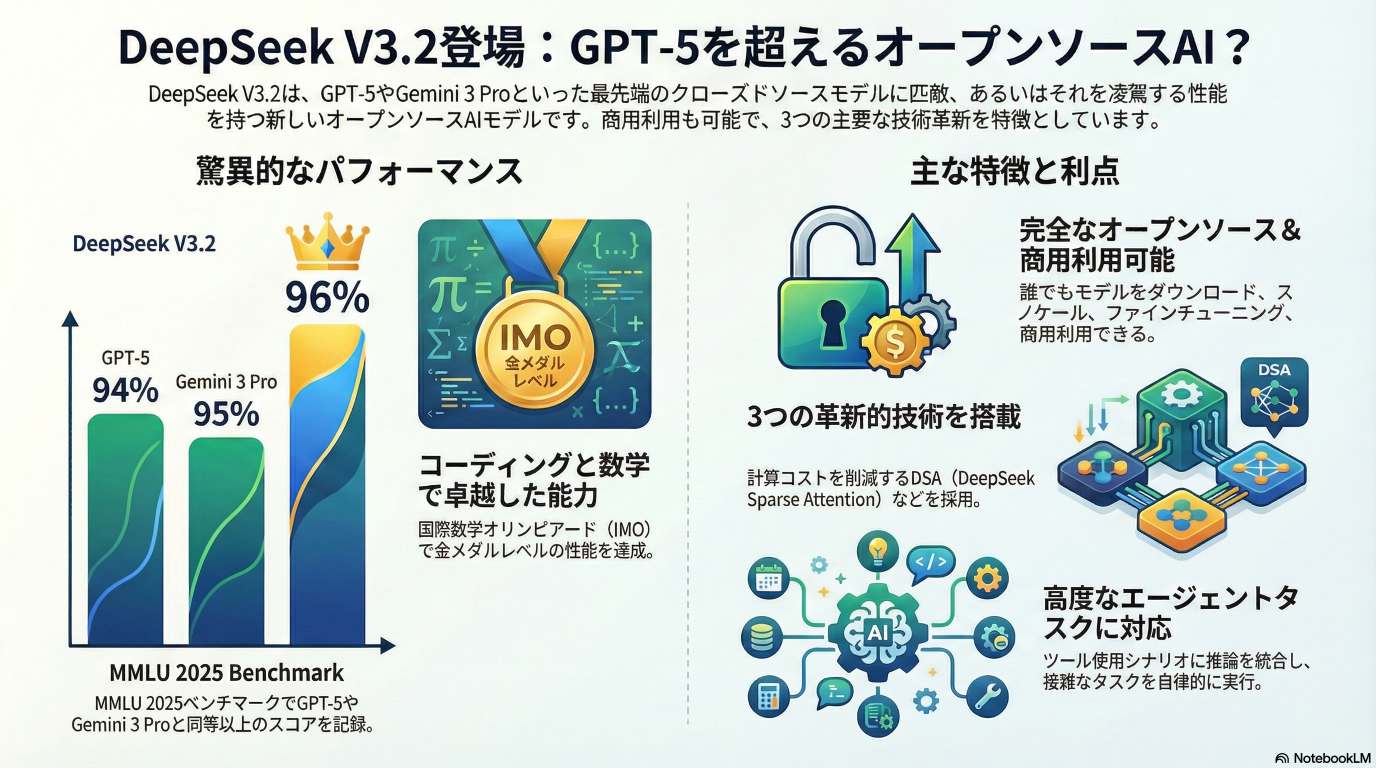
DeepSeekは、最新の大規模言語モデル「DeepSeek V3.2」をリリースした。このモデルには「DeepSeek V3.2 Special」と「DeepSeek V3.2 Thinking Model」の2つのバージョンが存在する。DeepSeek V3.2の最大の特徴は、オープンソースかつオープンウェイトでありながら、GoogleのGemini 3 ProやOpenAIのGPT-5といった業界をリードするクローズドソースモデルに匹敵、あるいは�それを凌駕するパフォーマンスを主要なベンチマークで示している点にある。
この卓越した性能は、3つの主要な技術革新によって支えられている。第一に、計算効率を大幅に向上させる「DeepSeek Sparse Attention (DSA)」。第二に、GPT-5レベルの性能を可能にする「スケーラブルな強化学習フレームワーク」。そして第三に、エージェントタスク能力を強化する「大規模なエージェントタスク合成パイプライン」である。
DeepSeek V3.2は、Webアプリ、API、およびHugging Faceを通じたダウンロードにより、研究者や開発者が自由かつ無料で利用できる。これにより、商用利用、スケーリング、ファインチューニングが可能となり、AI技術の民主化を促進する重要な一歩となっている。
主要テーマと分析
発表とモデルの概要
DeepSeekは、最新のAIモデル群であるV3.2を発表した。これには、「DeepSeek V3.2 Special」と「DeepSeek V3.2 Thinking Model」という2つの主要バージョンが含まれる。このリリースが特に注目されるのは、中国発のオープンソースモデルが、Google (Gemini)、OpenAI (GPT)、Anthropic (Claude) といった大手テック企業が提供する最先端のクローズドソースモデルと直接競合する性能レベルに達したことである。
DeepSeekは、モデルをリ��リースする際にその技術詳細や手法を公開する方針を貫いており、今回のV3.2に関しても、事前学習や事後学習のプロセスを詳述した研究論文が公開されている。
パフォーマンスとベンチマーク
DeepSeek V3.2は、複数の標準的なベンチマークにおいて、既存の最高性能モデルと同等、あるいはそれ以上の結果を示している。特に、MMLU 2025ベンチマークでは卓越したスコアを記録している。
| モデル | MMLU 2025 スコア |
|---|---|
| DeepSeek V3.2 Special | 96% |
| Gemini 3 Pro | 95% |
| GPT-5 | 94% |
| DeepSeek V3.2 Thinking | 93% |
| Claude 4.5 Sonnet | 87% |
MMLU以外にも、以下のベンチマークで優れたパフォーマンスが確認されている:
- HMT 2025 (Humanity Last Exam): 高い性能を発揮。
- Codeforces & SWE-bench: コーディング能力において優れた結果。
- Terminal: エージェント的なコーディングタスクに特化したベンチマークで高い性能。
- T-Eval & 2D-Catholon: その他の評価指標でも優れた結果。
さらに特筆すべきは、2025年の国際数学オリンピック (IMO) において、世界でもごく限られたAIシステムしか達成できていない「ゴールドメダルレベル」のパフォーマンスを実証したことである。
オープンソースの利点
DeepSeek V3.2の最も重要な側面の一つは、オープンソースかつオープンウェイトであるという点である。これは、手法や技術が非公開であるクローズドソースモデルとは対照的である。
- 透明性とアクセス性: ユーザーはモデルをダウンロードし、その構造を理解し、自由に利用できる。
- カスタマイズ性: ファインチューニングやスケーリングが可能であり、特定の用途に合わせた最適化が行える。
- 商用利用: 商用目的での利用が許可されており、ビジネスへの応用が容易である。
クローズドソースモデルでは、APIを介した利用に限定され、モデルの内部構造や学習データに関する情報はほとんど提供されないが、DeepSeekは完全な透明性を提供することで、AIコミュニティ全体の発展に貢献している。
3つの主要な技術革新
DeepSeek V3.2の高性能は、以下の3つの革新的な技術に基づいている。
- DeepSeek Sparse Attention (DSA): 複雑な問題を入力すると、モデルが処理するトークン数が増加し、計算負荷とコストが上昇するのが一般的である。DSAは、この計算量を削減しつつ、他のモデルがより多くの計算を費やして達成するのと同等レベルのパフォーマンスを維持する。これにより、効率と性能の両立が実現されている。
- スケーラ��ブルな強化学習フレームワーク: 堅牢な強化学習プロトコルと、スケーリングされた事後学習コンピューティングを実装。このフレームワークにより、モデルの性能はGPT-5やGemini 3 Proのレベルにまで引き上げられている。
- 大規模なエージェントタスク合成パイプライン: ツール使用シナリオに推論能力を統合するため、トレーニングデータを体系的に生成する独自の合成パイプラインを開発。これにより、モデルはエージェントとしてタスクを実行する能力が大幅に向上しており、複雑な指示にも的確に対応できる。
アクセシビリティと実用例
DeepSeek V3.2は、複数のチャネルを通じて広く利用可能である。
- Webアプリケーション: chat.deepseek.comにアクセスすれば、誰でも無料でモデルを試すことができる。
- API: api.deepseek.comを通じてAPIアクセスが可能。JSON出力、4Kおよび32Kのコンテキスト長、ツールコールなど、多様な機能に対応している。
- Hugging Face: モデル本体がHugging Faceで公開されており、システム要件を満たせばダウンロードしてローカル環境で実行、スケーリング、ファインチューニングが可能。
実用例として、ソースコンテキストの提供者は、DeepSeek V3.2に「フライト、ホテル、レンタカーを検索できる旅行予約サイトのフロントエンドUIを作成せよ」というプロンプトを与えた。その結果、モデルは要求通りのウェブサイトを開発した。��同様のプロンプトをGemini 3 Proにも与え、その結果と比較しており、DeepSeek V3.2の能力の高さを裏付けている。
AIモデル競合分析:DeepSeek V3.2 vs. GPT-5 vs. Gemini 3 Pro
序文
本レポートは、最新の大規模言語モデル(LLM)であるDeepSeek V3.2、GPT-5、そしてGemini 3 Proの技術仕様と性能を比較分析することを目的としています。近年のAIモデル市場では、クローズドソースモデルが主流を占める一方で、オープンソースモデルの台頭が著しくなっています。特に、DeepSeek V3.2のリリースは、オ�ープンソースモデルが性能面で最先端のクローズドソースモデルに匹敵、あるいは凌駕しうることを示す重要な出来事です。本分析が、AI開発者や研究者の方々にとって、これらの主要LLMの技術的能力と戦略的価値を評価し、自身のプロジェクトに最適なモデルを選択するための一助となることを目指します。
1. モデル概要と戦略的ポジショニング
AI開発の世界では、モデルは大きく「オープンソース」と「クローズドソース」の二つに分類されます。オープンソースモデルは、その設計や学習済みウェイトが公開されており、誰でも自由に利用、改変、再配布が可能です。これにより、透明性の確保やコミュニティによるイノベーションの加速が期待できます。一方、クローズドソースモデルは、開発企業が技術を非公開とし、主にAPIを通じてサービスとして提供します。これにより、品質管理や収益化が容易になるという戦略的利点があります。このセクションでは、分析対象となる3つのモデルが、この文脈でどのように位置づけられるかを見ていきます。
| モデル (Model) | 開発元 (Developer) | 主な特徴と開発モデル (Key Feature & Development Model) |
|---|---|---|
| DeepSeek V3.2 (Special & Thinking) | DeepSeek | オープンソース・オープンウェイトモデル。商用利用、スケーリング、ファインチューニングが可能。 |
| GPT-5 | OpenAI | クローズドソースモデル。内部の技術や手法は非公開。 |
| Gemini 3 Pro | クローズドソースモデル。内部の技術や手法は非公開。 |
DeepSeek V3.2の最大の特徴は、オープンソースであることです。これにより、ユーザーはモデルを直接ダウンロードし、自社のインフラ上でスケールさせ、特定の用途に合わせてファインチューニング(追加学習)を行うことができます。さらに、商用目的での利用も許可されており、これはAPI経由での利用が基本となるクローズドソースモデルにはない、大きな利点と言えます。
各モデルの戦略的ポジショニングを理解した上で、次にその客観的な性能を具体的な数値で比較し、その実力を検証します。
2. ベンチマーク性能の徹底比較
AIモデルの能力を客観的に評価する上で、標準化されたベンチマークテストは不可欠な役割を果たします。これらのテストは、言語理解、推論、数学、コーディングといった多岐にわたる能力を測定し、異なるモデル間の性能を公平に比較するための基準となります。本セクションでは、主要なベンチマークにおける各モデルのスコアを比較し、その性能を徹底的に分析します。
MMLU 2025 ベンチマークスコア
MMLU(Massive Multitask Language Understanding)は、モデルの幅広い知識と問題解決能力を測るための重要なベンチマークです。2025年版のスコアでは、オープンソースモデルの性能到達点を示す、注目すべき結果が明らかになりました。
| モデル | MMLU 2025スコア (%) |
|---|---|
| DeepSeek V3.2 Special | 96% |
| Gemini 3 Pro | 95% |
| GPT-5 | 94% |
| DeepSeek V3.2 Thinking | 93% |
| Claude 4.5 Sonet | 87% |
分析の結果、DeepSeek V3.2 Specialは、GoogleのGemini 3 ProやOpenAIのGPT-5といった主要なクローズドソースモデルを上回るスコアを記録しました。これは、オープンソースモデルが技術的性能において、業界をリードするクローズドソースモデルと互角以上に渡り合えることを明確に示しており、極めて重要な成果です。
その他の主要ベンチマークでの高評価
DeepSeek V3.2は、MMLU 2025以外にも、多様なベンチマークで優れた性能を発揮しています。
- HMMT 2025
- CodeForces
- SWE-bench
- Terminal
- T-Square Bench
- 2D-Catholon
特筆すべき成果:国際数学オリンピック
さらに特筆すべきは、DeepSeek V3.2が2025年国際数学オリンピック(IMO)において金メダルレベルの性能を達成したことです。これは、世界でもごく限られたAIシステムのみが到達できる極めて高い水準であり、その高度な数学的推論能力を証明しています。
これら多様なベンチマーク結果は、DeepSeek V3.2が特定のタスクだけでなく、幅広い領域で卓越した能力を持つことを裏付けています。次のセクションでは、この驚異的な性能を支える独自の技術について掘り下げていきます。
3. DeepSeek V3.2を支える3つの独自技術
DeepSeek V3.2が達成した優れたベンチマークスコアの背景には、単なる計算資源の投入だけでなく、革新的なアーキテクチャと学習手法が存在します。開発元であるDeepSeekは、性能と効率を両立させるために、以下の3つの主要な独自技術を導入したと発表しています。
3.1. DeepSeekスパースアテンション (DSA)
DSAは、モデルが複雑な問題に取り組む際の計算負荷を劇的に削減する技術です。従来のモデルでは、問題が複雑になるほど計算量が増大し、処理時間とコストが膨らんでいました。しかし、DSAを用いることで、DeepSeek V3.2は計算量を抑制しながらも、他のモデルがより多くの計算を行って達成するのと同等以上の性能を維持することができます。この計算効率の高さは、モデルの運用コストを下げ、より幅広い応用を可能にする革新的なアプローチです。
3.2. スケーラブルな強化学習フレームワーク
DeepSeek V3.2は、堅牢な強化学習プロトコルと、スケーリングされた事後学習計算を実装したフレームワークを採用しています。この高度な強化学習フレームワークにより、モデルはより複雑な指示やニュアンスを理解し、質の高い応答を生成する能力を磨き上げています。このアプローチが、GPT-5やGemini 3 Proといった最先端モデルに匹敵、あるいはそれ以上の性能を実現する上での重要な鍵となっています。
3.3. 大規模なエージェントタスク合成パイプライン
今日のAIモデルには、単に情報を提供するだけでなく、ツールを使いこなし、自律的にタスクを遂行する「エージェント」としての能力が求められています。DeepSeek V3.2は、この要求に応えるため、ツール使用シナリオに推論能力を統合する新しい合成パイプラインを開発しました。このパイプラインは、トレーニングデータと必要なスキルを体系的に自動生成し、モデルに組み込むことで、エージェントとしてのタスク実行能力を飛躍的に向上させています。このパイプラインの採用が、TerminalベンチマークやSWE-benchにおける卓越した性能の直接的な要因と考えられます。
これら3つの技術が相互に作用し、DeepSeek V3.2の総合的な高性能と高い効率性を実現しています。次のセクションでは、これらの技術が開発者にとってどのような実用的な価値を持つのかを考察します。
- 実用性とアクセシビリティの評価
AIモデルの真価は、その理論的な性能だけでなく、開発者が実際にどれだけ容易にアクセスし、現実の課題解決に活用できるかによって決まります。この点において、DeepSeek V3.2はオープンソースモデルならではの優れたアクセシビリティと実用性を提供しています。
開発者は、以下の複数の方法でDeepSeek V3.2を利用することができます。
- Hugging Face: モデルのウェイトが公開されており、誰でもダウンロードが可能です。これにより、ローカル環境での実行や、特定のデータセットを用いたファインチューニング、さらには独自のアプリケーションへの組み込みやスケーリングが自由に行えます。
- 公式API (api.deepseek.com): 手軽にモデルの機能を試したい開発者向けに、公式APIが提供されています。JSON出力、最大32Kトークンのコンテキスト長、ツールコール(外部機能連携)といった高度な機能も利用でき、迅速なプロトタイピングやサービス開発を支援します。
- Webアプリ (chat.deepseek.com): 専門的な知識がないユーザーでも、ブラウザから直接モデルの性能を試すことができるWebインターフェースが用意されています。これにより、誰でも手軽にDeepSeek V3.2の対話能力を体験できます。
実用例:コーディングタスクでの性能
DeepSeek V3.2の実用性を示す具体例として、「フライト、ホテル、レンタカーを検索できる旅行予約サイトのフロントエンドUIを作成する」というコーディングタスクが挙げられます。このタスクにおいて、DeepSeek V3.2は非常に高品質なコードを生成し、同じプロンプトに対するGemini 3 Proの結果と比較しても、その性能は極めて競争力が高いことを示しました。これは、モデルが複雑な要求を正確に理解し、実践的なコードを生成する高い能力を持っていることを示しています。
このように、DeepSeek V3.2が提供する高いアクセシビリティと多様な利用方法は、その技術的な優位性と相まって、オープンソースモデルとしての価値をさらに高めています。最後に、本レポート全体の結論をまとめます。
5. 総括:AI開発の未来への示唆
本分析の結果、DeepSeek V3.2は単なる高性能モデルではなく、オープンソースAIがクローズドソースの最前線に到達したことを示す、市場の転換点となる存在であることが明らかとなった。オープンソースでありながら、性能面で業界トップのクローズドソースモデルと互角以上に渡り合うその存在は、AIエコシステム全体に大きな影響を与えるでしょう。
本分析から得られた結論は、以下の3つの要点に集約されます。
- トップクラスの性能 DeepSeek V3.2は、MMLU 2025や国際数学オリンピック(IMO)レベルのタスクを含む主要なベンチマークにおいて、GPT-5やGemini 3 Proといった最先端のクローズドソースモデルと競合し、一部ではそれを上回る性能を証明しました。
- オープンソースの戦略的価値 モデルがオープンソース・オープンウェイトであることが、開発者コミュニティに透明性、カスタマイズ性、そして商用利用の自由をもたらします。これにより、特定の企業による技術独占のリスクが低減され、より健全で競争力のあるAIエコシステムの形成が促進されるでしょう。
- 革新的技術の採用 DeepSeekスパースアテンション(DSA)やスケーラブルな強化学習フレームワークといった独自技術は、高性能と計算効率という二律背反の課題を解決するアプローチです。これは、今後のモデルアーキテクチャが目指すべき方向性を示唆しています�。
結論として、DeepSeek V3.2は、オープンソースモデルが性能面でクローズドソースモデルに追いつき、追い越す時代の到来を象徴する存在です。AI開発者は今後、プロジェクトの要件やコスト、カスタマイズの自由度といった多角的な視点からモデルを選択する上で、DeepSeek V3.2という極めて強力な選択肢を手にすることになります。
情報源
動画(7:13)
DeepSeek V3.2 Released! Better than GPT-5 & Gemini 3 Pro? (Full Review) | 407
600 views 2025/12/02
(2025-12-02)