深層推論(DeepSeek Math V2) とコンパクト OCR(Hunuen OCR) の驚異的な進化
(全体俯瞰 : AI 生成) click で拡大
要旨
深層推論とコンパクトOCRの驚異的な進化
本書は、中国企業による二つの非常に影響力のあるAIモデルの発表について分析しています。一つ目は、DeepSeek Math V2であり、これは国際数学オリンピック(IMO)レベルの性能を持ち、最終的な答えだけでなく、論理的な厳密さを報酬とする自己検証型推論フレームワークを採用しています。
この構造は、生徒・教師・監督者から成り、誤謬を最小限に抑え、正直な間違いの認識に対して報いるように設計されています。次に、TencentがリリースしたHunuen OCRは、わずか10億のパラメーターを持つコンパクトな専門モデルです。その小さなサイズにもかか�わらず、このエンド・ツー・エンドのシステムは、複雑な文書処理において、はるかに大規模な汎用ビジョン言語モデルを上回る性能を発揮しています。
これらの進展は、高精度な専門分野特化型AIが、巨大な汎用モデルと競合する新たなトレンドを示唆しています。
目次
- 要旨
- 新規AIモデルに関するブリーフィング:DeepSeek Math V2とHunyuan OCR
- Tencent Hunuen OCR(10億パラメータ)
- Deepseek Math V2
- 情報源
新規AIモデルに関するブリーフィング:DeepSeek Math V2とHunyuan OCR
要旨
最近発表された2つのAIモデル、DeepSeek Math V2とTencentのHunyuan OCRは、それぞれ数学的推論と光学文字認識(OCR)の分野で大きな進歩を示している。これらのモデルは、AI開発における重要なトレンド、すなわち巨大な汎用モデルと並行して、特定の領域で優れた性能を発揮する高度に専門化されたコンパクトなモデルの台頭を浮き彫りにしている。
DeepSeek Math V2は、国際数学オリンピック(IMO)の金メダルレベルの性能を持つとされ、最終的な答えの正しさだけでなく、証明の厳密性や論理性を重視する「自己検証可能な推論」という革新的なアプローチを採用している。独自の「生徒-教師-監督者」フレームワークと、間違いを正直に認めることを報酬とする学習メカニズムにより、AIの推論能力を新たな次元へと引き上げている。
一方、TencentのHunyuan OCRは、わずか10億パラメータというコンパクトなサイズでありながら、はるかに大規模な汎用視覚言語モデル(VLM)を特定のOCRタスクで凌駕する性能を達成した。複雑なパイプラインを単一のエンドツーエンドモデルに置き換え、文書のレイアウトを空間的に理解する独自のアーキテクチャにより、実社会の多様な文書処理タスクにおいて卓越した精度と効率を実現している。
本ブリーフィングでは、これら2つのモデルの技術的ブレークスルー、性能、そしてAI分野全体に与える影響について詳細に分析する。
1. DeepSeek Math V2: 数学的推論の新たなフロンティア
DeepSeek Math V2は、数学的問題解決能力を飛躍的に向上させたモデルであり、その核心は最終的な答えだけでなく、そこに至るまでの論理的プロセスを重視する設計思想にある。
1.1 概要と主要な性能
DeepSeek Math V2は、事前の大々的な宣伝なくHugging Face上で公開された。Deepseek V3.2 to Xpaceを基盤として構築されており、Googleが構造化推論のために開発したGemini Deepthinkを上回る性能を持つと主張されている。
その性能は各種ベンチマークで証明されている:
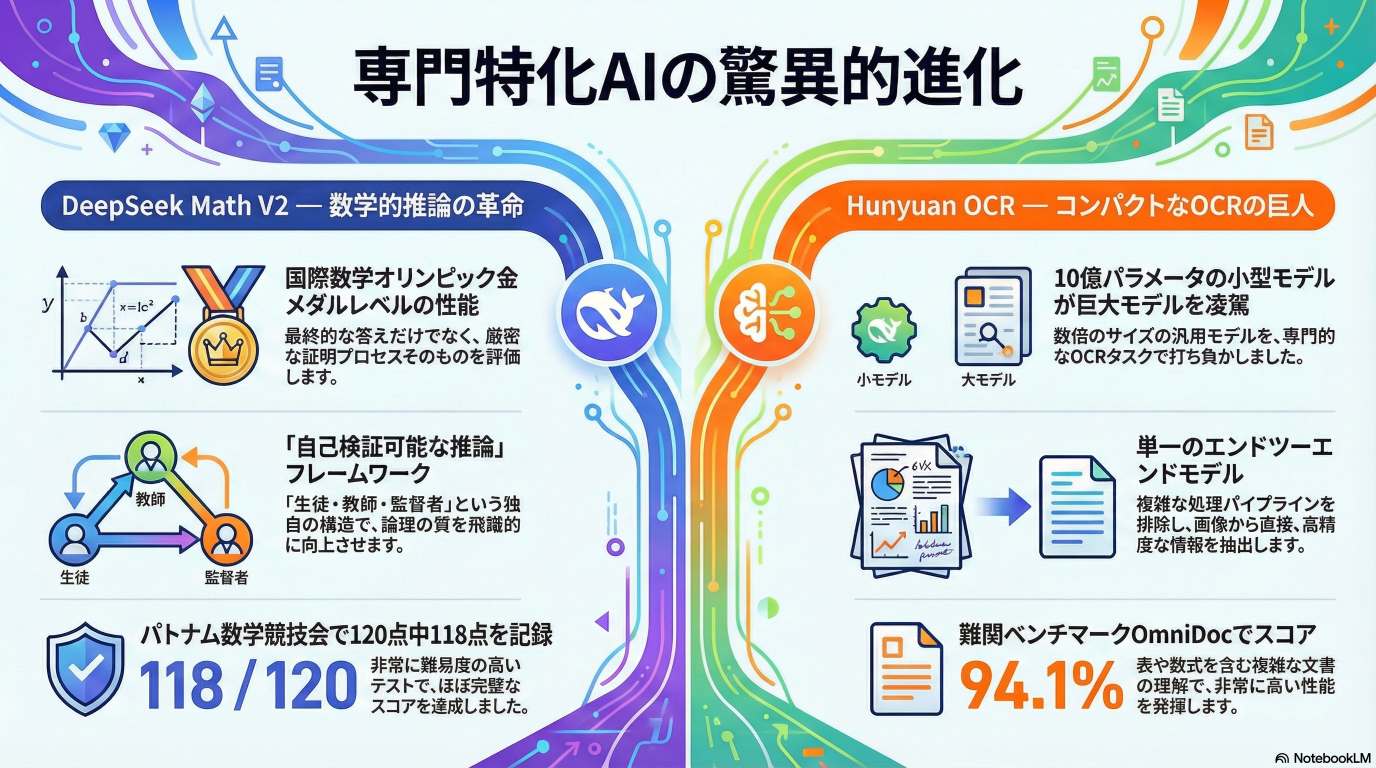
- 国際数学オリンピック(IMO)証明ベンチマーク: 基本ベンチマークで約99%のスコアを達成し、金メダルレベルの性能を示す。
- 2024年パトナム数学コンテスト: 120点満点中118点という、ほぼ完璧に近いスコアを記録した。これはオープンモデルとしては異例の高さである。
1.2 中核理念:「自己検証可能な推論」
従来の数学AIモデルは、最終的な答えが正しいかどうかに焦点を当てていた。しかし、このアプローチでは、プロセスを理解せずに偶然正しい答えにたどり着くことが可能であり、厳密な証明が求められる高度な問題では限界があった。
DeepSeek Math V2は、この問題を解決するために「自己検証可能な推論(self-verifiable reasoning)」という原則に基づいている。これは、単に問題を解くだけでなく、その解法を証明し、自ら検証し、間違いを認める能力を重視するものである。数学の競技会や学術的な証明が、最終的な数値だけでなく、導出過程の厳密さや論理性を評価するのと同じアプローチである。
1.3 革新的な学習フレームワーク:「生徒-教師-監督者」モデル
この理念を実現するため、DeepSeekは独創的な三層構造の学習フレームワークを構築した。
- Examiner(教師): 証明を検証する専門モデル。最終的な答えだけでなく、証明全体の流れを読み、論理的な欠陥や不備を指摘する。評価は二元的なものではなく、以下の3段階の評点システムを用いる。
- 1点: 完璧で厳密な導出。
- 0.5点: 方向�性は正しいが、記述が雑である。
- 0点: 論理的な誤りやステップの欠落。
- Metaverifier(監督者): 「教師」モデルの評価を検証するモデル。「教師」が誤りを幻覚(ハルシネーション)したり、不当な評価を下したりすることを防ぐ。このクロスチェック機能により、評価の信頼性が大幅に向上する。
- Generator(生徒): 実際に証明を生成するモデル。証明を出力した後、直ちに自己評価を行う必要がある。
1.4 報酬システムと自己進化ループ
このフレームワークの最大の特徴は、報酬の与え方にある。モデルは正しさだけでなく、正直さに対して報酬を与えられる。もし自らの証明に欠陥があることを正直に認めれば報酬が与えられ、逆に自信過剰に「問題ない」とごまかそうとすれば罰せられる。これにより、モデルは自信を幻覚するのではなく、自身の推論の弱点を内省し、修正する能力を学習する。
このシステムは、完全に自動化された閉ループのエコシステムを形成する。
- 「生徒」が多数の解答を生成する。
- 「教師」がそれらをすべて採点する。
- 採点が困難だった問題や解けなかった問題が、新たな学習データとなる。
- これにより、「教師」と「生徒」が共に進化していく。
このアプローチは、人間の数学者による大量の採点作業を必要とせず、システムが自律的に進化することを可能にする。
1.5 技術的ブレークスルーと影響
DeepSeek Math V2の真のブレークスルーは、強化学習の報酬を「最終的な答えの正しさ」から「推論の質、論理、自己修正能力」へと転換した点にある。これにより、ハルシネーションが大幅に減少し、思考の連鎖が安定し、モデルの動作が人間の数学者の働き方とより一致するようになった。これは、AIが単なる計算機ではなく、真の数学的推論能力を獲得するための重要な一歩と言える。
2. Tencent Hunyuan OCR: コンパクトな専門モデルの台頭
Tencentが発表したHunyuan OCRは、巨大化が進むAIモデルの潮流とは一線を画し、特定のタスクに特化した小型モデルの優位性を示す画期的な例である。
2.1 概要と主要な性能
Hunyuan OCRは、わずか10億パラメータのOCR専門モデルでありながら、Qwen 3 VL(235億パラメータ)やGemini 1.5 Proといった数倍から数十倍�の規模を持つ大規模な汎用VLMを、OCR関連タスクにおいて凌駕する性能を達成している。
| ベンチマーク / タスク | スコア / 成果 |
|---|---|
| Tencent内部ベンチマーク | 70.92% |
| OmniDoc (公開文書理解ベンチマーク) | 94.1% |
| Wild OmniDoc (劣悪な条件下での文書) | 85%超 |
| DocVQA-ML (14言語対応) | 91.03% (最先端) |
| 情報抽出タスク | 92%超の精度 |
| OCRBench | 860 |
| ICDAR 2025 DIMPコンペティション | 小規模モデル部門で1位 |
2.2 エンドツーエンドのアーキテクチャ
従来のOCRシステムは、「テキスト検出」「切り出し」「認識」「レイアウト再構築」といった複数のステップからなる複雑なパイプラインに依存していた。Hunyuan OCRはこれを廃し、画像を入力すると単一のフォワードパスでテキスト検出、文書解析、情報抽出、翻訳、さらにはVQA(視覚的な質問応答)までを処理する、単一のエンドツーエンドモデルとして設計されている。これにより、パイプラインの途中でエラーが発生するリスクがなくなり、処理が非常にクリーンになる。
2.3 主要な技術的要素
この高性能を支える技術は以下の通りである。
- Visual Encoder: SigLIP V2-400Mを基盤とし、画像を正方形にトリミングするのではなく、元の解像度とアスペクト比のまま扱えるように拡張されている。これにより、レシートや表、多段組の文書など、多様な形状の文書の構造情報が失われるのを防ぐ。
- Adaptive Connector Module: 視覚トークンを効率的に圧縮し、テキスト関連の重要な詳細を保持しながら、言語モデルの負荷を軽減する。
- Language Model & XD-RoPE: わずか0.5億パラメータの言語モデルだが、「XD-RoPE」という技術を搭載している。これは、位置情報を「テキスト」「ページの高さ」「ページの幅」「時間(動画用)」の4次元で理解する。これにより、多段組のPDFや表、フォーム、さらには動画内の字幕のような複雑な空間的レイアウトを正確に解析できる。
2.4 学習プロセスと報酬設計
学習は、純粋なテキスト、合成OCRデータ、多言語サンプル、長文コンテキストのコーパスなどを組み合わせた多段階のプロセスで行われた。コンテキストウィンドウは最大32Kまで拡張され、長文の文書にも対応可能である。
強化学習では「検証可能な報酬シグナル」が用いられる。モデルの出力(バウンディングボックス、テキスト、JSON形式など)が、正解データと構造的に完全に一致した場合にのみ報酬が与えられ、フォーマットが崩れたり不正確だったり��した場合は報酬ゼロとなる。これにより、非常にクリーンで信頼性の高い構造化出力を生成する能力が鍛えられた。
2.5 専門モデルの重要性
Hunyuan OCRの成功は、AI開発における転換点を示唆している。
- 効率性: 巨大なパイプラインを、単一の合理化されたモデルに置き換えることができる。
- 実用性: プロダクション環境に導入可能なほど小型である。
- 多言語性: 100以上の言語に対応する。
- 性能: 実社会で重要となるタスクにおいて、はるかに大規模な汎用モデルを上回る性能を発揮する。
これは、高度に専門化されたコンパクトなモデルが、AIの実用化を加速させる重要な鍵であることを示している。
3. 結論と考察
DeepSeek Math V2とHunyuan OCRは、AI開発における2つの異なる、しかし同様に重要な方向性を示している。
- DeepSeek Math V2は、推論のプロセスそのものを検証・改善することで、AIがより信頼性の高い、人間のような思考能力を獲得する道筋を示した。これは、科学技術や学術研究など、厳密な論理が求められる分野へのAI応用を加速させる可能性がある。
- Hunyuan OCRは、巨大な万能モデルを追求するだけでなく、特定の問題領域に最適化された高効率な専門モデルを開発することの価値を証明し�た。これは、AI技術をより多くの産業や実用的なアプリケーションに迅速に展開するための現実的なアプローチである。
これらのモデルが提起する「AIの未来は、高度に専門化された小型モデルと、すべてをこなす巨大な汎用モデルのどちらが主流になるのか」という問いは、今後のAI開発における中心的なテーマとなるだろう。
Tencent Hunuen OCR(10億パラメータ)
このDeepSeekとTencentの最新AIモデルの進展というより大きな文脈において、Tencent Hunuen OCR(10億パラメータ)のリリースは、特殊化されたコンパクトなモデルが、より大きな汎用システムに匹敵、あるいはそれを上回る能力を示しているという、AI開発における重要な転換点を象徴しています。
ソースがTencent Hunuen OCRについて強調している点は以下の通りです。
1. 驚異的なパフォーマンスとサイズの不均衡
- Hunuen OCRは10億パラメータのOCR専門家モデルです。
- この小さなモデルが、OCR中心のタスクにおいて、Qwen 3 VL4BやGemini 2.5 Pro、さらには一部の商用APIといった主要なマルチモーダル巨大モデルを打ち負かしているという事実は、本来このサイズではあり得ないことです。
- これは、DeepSeek Math V2が数学推論においてGPT-4やGemini Ultraのレベルで実行されたのと同様に、AIの進化が非常に速いことを示しています。
2. 画期的なエンド・ツー・エンドのアーキテクチャ
- 従来のOCRシステムは、テキストの検出、切り出し、認識、レイアウトの再構築といった複数のステップを持つ大きなパイプライン構造に依存していました。
- Tencentはこれを疑問視し、Hunuen OCRを単一の「エンド・ツー・エンド」モデルにまとめ上げました。
- このモデルは、外部モジュールに依存することなく、1回の順伝播でテキストスポッティング、ドキュメント解析、情報抽出、翻訳、さらにはVQA(視覚的質問応答)までを処理します。これにより、途中で壊れる可能性のあるツールチェーンが存在しないため、システムは非常にクリーンだとされています。
3. 現実世界のドキュメント処理に特化した技術
Hunuen OCRのバックボーンには、現実世界の複雑なドキュメントに対応するための巧妙な設計が施されています。
- オリジナル解像度での処理: 従来のシステムのように画像を正方形にトリミングするのではなく、視覚エンコーダ(Siglet V2-400M基盤から拡張)は、元の解像度とアスペクト比で画像を取り込むことができます。これは、長いレシート、幅の広いテーブル、複数列のページなど、あらゆる形状とサイズで提供される実際のドキュメントにおいて、構造を失わないために非常に重要です。
- 4次元の空間理解(XD-ropey): 言語モデル(わずか0.5Bパラメータ)には「XD-ropey」という技術が搭載されており、トークンを単なるフラットなシーケンスとして扱うのではなく、テキスト自体、ページの高さ、ページの幅、そして時間(ビデオフレーム用�)という4つの次元で位置関係を理解します。これにより、複数列のPDFを解析したり、ページをまたぐ流れを追跡したり、テーブルやフォームを処理したり、さらには動画フレーム内の動く字幕を読み取ったりすることが可能になります。
4. 検証可能な報酬による強化学習
- Tencentは、教師あり学習の後、検証可能な報酬シグナルを用いた強化学習(RL)によってモデルをさらに強化しました。
- このシステムでは、出力がグラウンドトゥルースの構造(正しいバウンディングボックス、正しいテキスト、正確な翻訳)と完全に一致した場合にのみ報酬が与えられます。
- 出力が破損したJSONやフォーマットから逸脱した場合、報酬はゼロになります。この厳格な訓練が、構造化された出力のクリーンさを保つ理由です。
5. ベンチマークでの優れた結果
Hunuen OCRは、その小さなサイズにもかかわらず、困難なベンチマークで高いスコアを達成しています。
- OmniDoc(最も難しい文書理解ベンチマークの一つ)では、全体で94.1%�を記録しました。
- 照明が劣悪な下で再撮影されたドキュメントを扱うWild OmniDocでも85%以上を維持しています。
- 英語と中国語以外の14言語をカバーするDOC MLでは91.03%を達成し、セット全体で最先端の結果(state-of-the-art)を樹立しました。
- 情報抽出タスクでは92%以上の精度を達成し、小型モデルとしてはDeepSeek OCRを凌駕し、Qwen 3 VL2BやGemini 2.5 Proのようなモデルに非常に近い位置につけています。
- ICDAR 2025 DIMPコンペティションの小型モデル部門で、英語から中国語へのドキュメント翻訳で第1位を獲得しました。
より大きな文脈
Hunuen OCRは、DeepSeek Math V2が数学的推論における自己検証能力を強調したのと同様に、「専門性」と「効率性」の価値を示しています。
このモデルは、100以上の言語に対応し、本番環境での使用に適したほど小型であり、現実世界で重要なタスクにおいて、より大規模な汎用ビジョン言語モデル(VLM)を打ち負かしています。この進展は、大規模なパイプラインを単一の合理化されたモデルに置き換える「コンパクトなOCRスペシャリスト」の台頭を感じさせるものであり、AI競争におけるエキサイティングな変化として捉えられています。
これは、巨大な汎用モデルが万能薬として機能するのではなく、特定の困難なタスクを非常に効率的��かつ正確に解決するために設計された、専門分野に特化した高性能な「ツール」が登場している状況に例えることができます。それは、巨大なスイスアーミーナイフ(汎用VLM)が、特定の目的のために鋭く研ぎ澄まされた外科用メス(Hunuen OCR)に、その専門分野で性能を上回られるようなものです。
Deepseek Math V2
DeepSeekとTencentの最新AIモデルの進展というより大きな文脈において、DeepSeek Math V2のリリースは、AIが単なる「正解」を出す段階から、「推論を検証し、論理的な厳密性を維持する」段階へと移行していることを明確に示しています。
ソースがDeepSeek Math V2について強調している主な点は以下の通りです。
1. 驚異的な数学推論能力と目標性能
- DeepSeek Math V2は、国際数学オリンピック(IMO)の金メダルレベルの性能を発揮する数学モデルです。
- DeepSeekは、このモデルが、Googleが構造化推論のために特別に構築したモデルであるGemini Deepthinkの性能を上回ると主張しています。
- その前バージョンであるDeepSeek Math 7Bは、すでに昨年の時点でGPT-4やGemini Ultraと同等の数学タスク性能を発揮しており、Math V2はそれを基盤としています。
2. 自己検証可能な推論(Self-Verifiable Reasoning)の原則
DeepSeek Math V2の真のブレークスルーは、その独自のフレームワークにあります。従来のAI数学システムが最終的な答えの正誤のみを重視していたのに対し、DeepSeek Math V2はプロセス、厳密性、論理、および導出を重視して設計されました。
- 設計原則: このモデルは、「質問に答えるだけでなく、それを証明し、チェックし、間違いを認める」という自己検証可能な推論という一つの大きな原則を中心に設計されました。
- 従来の限�界の打破: DeepSeekは、正解のみを重視するシステム(AIMのようなベンチマークで優れていても)は、適切な厳密な証明を示すよう求められると崩壊してしまうことに気づきました。
- 強化学習の革新: 一般的なLLMは、推論のための強化学習において最終的な答えの正しさに報酬を依存させますが、このシステムはその制限を打破し、推論の質、論理、そして自身の誤りを検出する能力に報酬を与えます。これにより、ハルシネーションが大幅に減少し、連鎖的思考(Chain of Thought)がより安定し、モデルの動作が実際の数学者の作業方法とより一致するようになります。
3. スマートな訓練構造:「学生・教師・監視者」のコンセプト
DeepSeek Math V2は、「学生・教師・監視者(Student-Teacher-Supervisor)」という、数学的AIとしては最も賢い訓練構造の一つを中心に構築されています。
- 1. 鑑定者(Examiner/Teacher): これは専用の証明検証モデルであり、オリンピックの採点者として機能します。最終的な答えだけでなく、証明全体を読み通し、何が良いか、何が欠けているか、何が完全に間違っているかを説明します。
- 採点はバイナリではなく、3点システムを使用します(完璧な厳密な導出に1点、大体正しいがずさんな場合に0.5点、論理的誤りや欠落ステップに0点)。
- 2. メタ検証者(Metaverifier/Supervisor): 教師役(鑑定者)がエラーを幻覚したり、ランダムに証明を罰したりする場合があるため、追加された層です。監視者の仕事は、証明をチェックすることではなく、教師のコメントが実際に理にかなっているかどうかをチェックすることです。この追加層が、システムが一つのモデルの判断を信用せず、相互チェックを行うことで精度を大幅に向上させます。
- 3. 学生(Student/Generator): 証明を生成するモデルですが、出力後すぐに自己評価も行います。モデルは、正しさだけでなく、正直さに対して報酬を与えられます。間違いを犯し、その欠陥を正直に認めた場合、報酬を受け取ります。ごまかそうとした場合、罰せられます。これにより、モデルは証明を深く考え、弱点を反省し、自信を幻覚するのではなく問題を修正するようになります。
4. ベンチマークでの具体的な成果
この訓練構造の結果、驚異的なベンチマーク結果を達成しています。
- IMO Proof Bench: 厳しいオリンピック証明問題のセットで、基本的なベンチマークで99%近くを�記録しました。
- Putnam Test(2024年): 非常に難しいことで知られるこのテストで、120点中118点というほぼ完璧なスコアを獲得しました。これはオープンモデルとしては異例の数字です。
より大きな文脈(Tencent Hunuen OCRとの関連)
DeepSeek Math V2とTencent Hunuen OCRの進展は、AI開発における2つの主要な方向性を示しています。
- DeepSeek Math V2: 推論の質と自己検証能力という、汎用LLMが苦戦する認知的な上級タスクにおいて、人間の専門家レベルに到達するためのフレームワークの革新を示しています。
- Tencent Hunuen OCR: 専門性と効率性を追求し、特殊なタスク(OCR)において、非常に小さなモデル(10億パラメータ)が、より大規模な汎用モデル(Gemini 2.5 Proなど)を凌駕できることを示しました。
これらの進展は、AIの進化が非常に速いことを認識させる瞬間であり、巨大な「オールインワン」システム(Geminiなど)と、特定の困難なタスクを驚くべき精度と効率で解決するために設計された高性能な「専門家」モデルとの間の競争が激化していることを示唆しています。
DeepSeek Math V2は、AIを単なる暗記マシンから、厳密な論理を�検証できるアカデミックな共同研究者へと進化させるための青写真を提供しています。このアプローチは、数学者が実際の証明に取り組む方法をAIモデルが模倣するように強制するものです。
DeepSeek Math V2の自己検証フレームワークは、学生が数学の答案を作成した後、自分で採点し、さらにその採点結果を上級の教師がチェックするという、厳格なアカデミックなレビュープロセスを自動化していることに似ています。この多層的なチェック機構が、単に答えを出すだけでなく、その論理的な道のりが完璧であることを保証するのです。
情報源
動画(11:30)
DeepSeek's New AI Just Surpassed Gemini 3 DeepThink...
https://www.youtube.com/watch?v=mSDsLpMogtM
(2025-11-30)